
数据清理三类大题
数据清理:(由于讲的太多,而且难以详细整理,故而只能迫于应试而只记录做题方法)
一.清理噪声数据步骤:
1.步骤
2.类型:

3.练习:
1.已知一组价格数据:10、19、26、12、7、21、15、36、27、42、38、
3、16、30,现用等深(深度为5)分箱方法对其进行平滑(向下取整)。2.已知一组价格数据: 10、19、26、12、7、21、15、36、27、42、38、
3、16、30 ,现用等宽(宽度为10)分箱方法对其进行平滑(向下取整)。
4.总结:
先排序,再分箱,然后平滑。
深度即数量,宽度即距离
二.数据变换—规范化
数据规范化:将数据按比例缩放至一个小的特定区间:
1)最小—最大规范化:假定minA和maxA分别为属性A的最小和最大值,
则通过下面公式将A的值映射到区间[new_min, new_max]中的v’: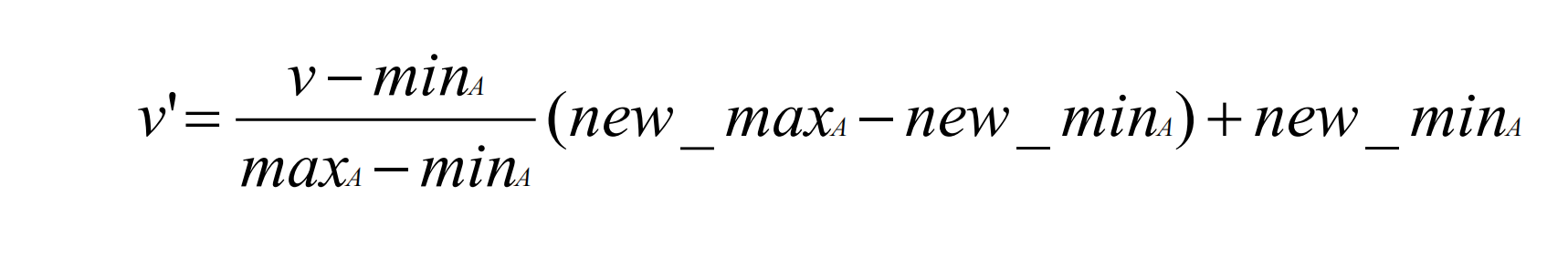
例:假定属性income的最小与最大值分别为$12000和$98000,可根据最
小—最大规范化方法将其范围映射到[0,1],如:属性值$73600将变换为:
[(73600-12000)/(98000-12000)]*(1-0)+0=0.716ps:另两种见PPT
三.数据归约PCA:
(1)计算步骤:
1.计算均值
2.将原数据列向量化,然后将矩阵零均值化(每个数都减去对应的均值)
3.根据公式算出协方差
4.计算特征值以及特征向量
5.确定贡献率,选择大的那个对应的特征向量
6.将原数据投影到新的基(特征向量横着写与一开始的矩阵相乘)(2)例题: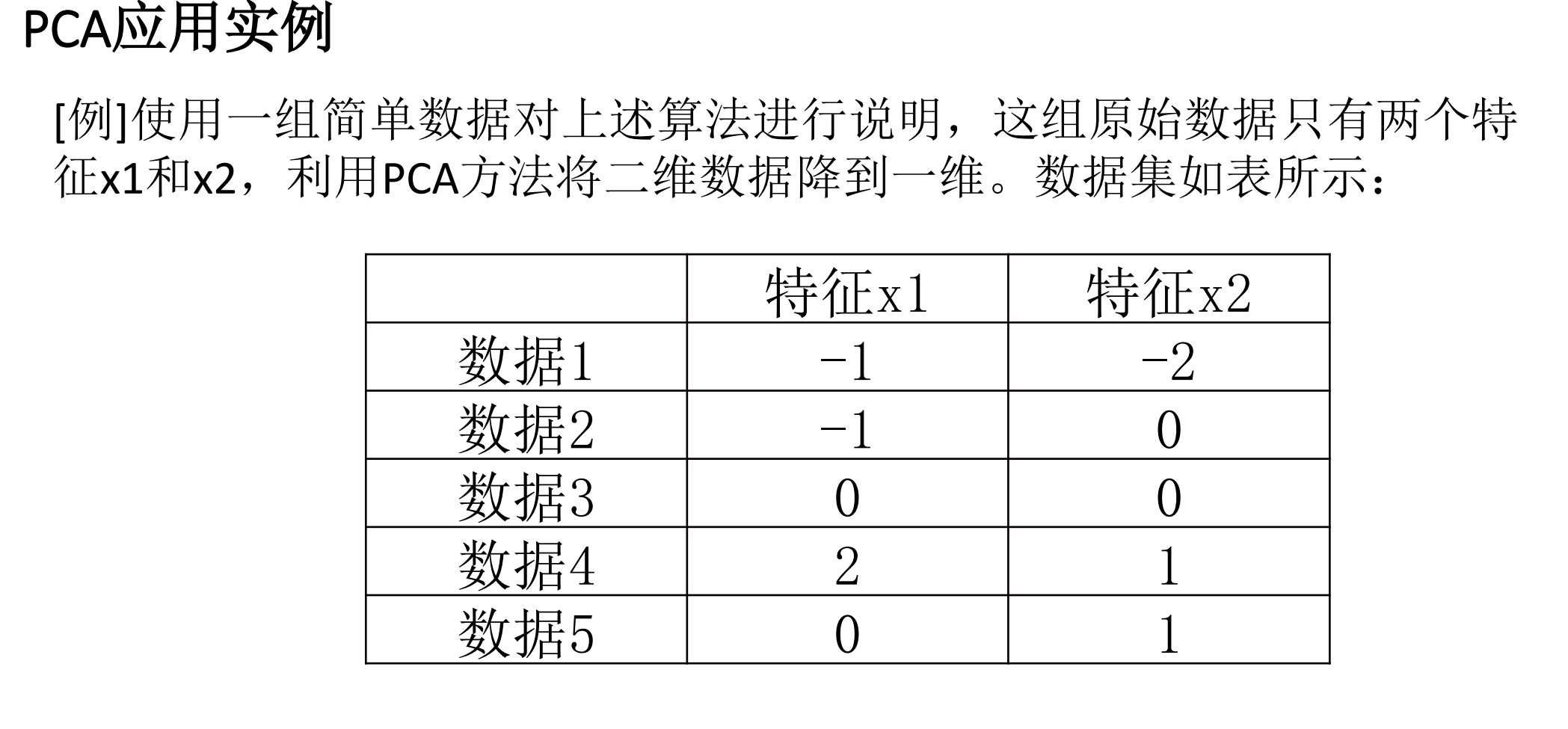


注:解答最后答案是错的,正确答案是[-3,-1.0,3,1]
ps:此外还有一些简单概念,例如3-4-5规则这类,详见PPT
四.关联规则挖掘
1.Apriori算法:
步骤:

例子:
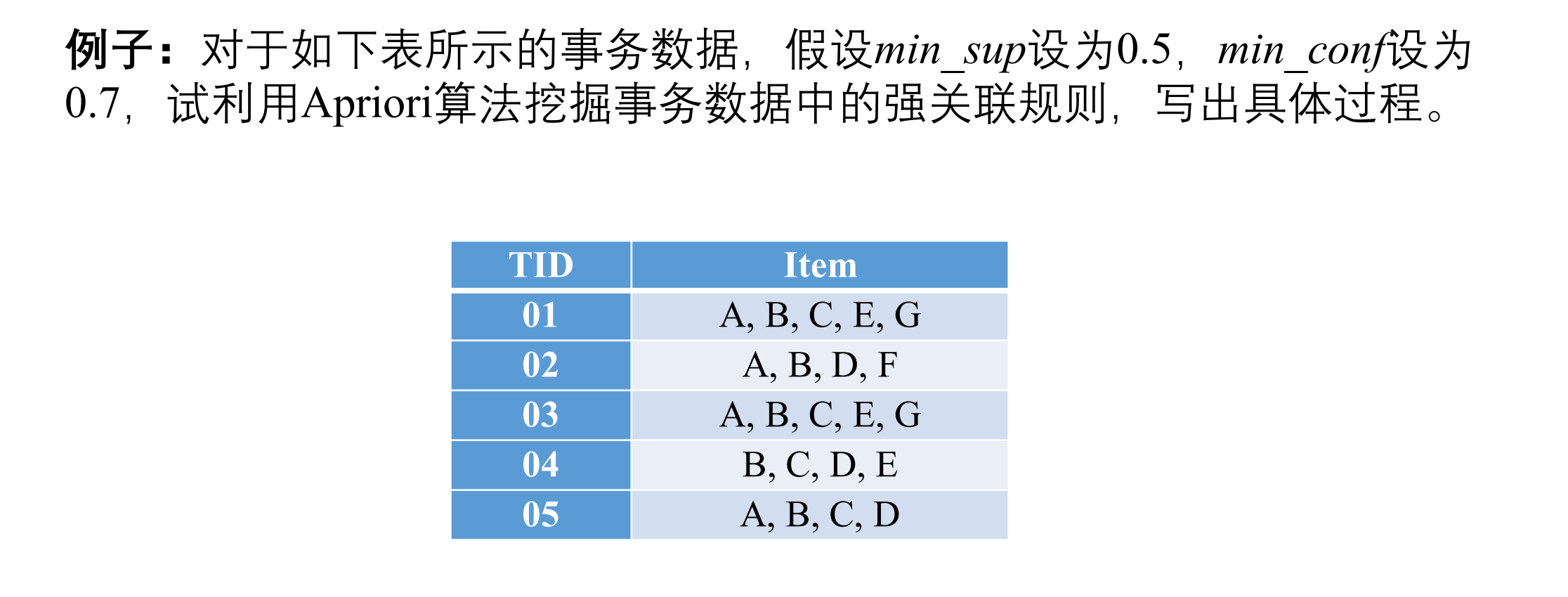


2.FP Growth算法:
一.FP-growth算法发现频繁项集的过程:
(1)构建FP树;
(2)从FP树中挖掘频繁项集。FP-Tree:将事务数据表中的各个事务数据项按照支持度计数排序后,把每个事
务中的数据项按支持度计数的降序依次插入到一棵以NULL为根结点的树中,
同时在每个结点处记录该结点出现的支持度。条件模式基:包含在FP-Tree中与后缀模式一起出现的前缀路径的集合,也就是
同一个频繁项在FP树中的所有节点的祖先路径的集合。条件树:将条件模式基按照FP-Tree的构造原则形成的一个新的FP-Tree子树。
二.例子: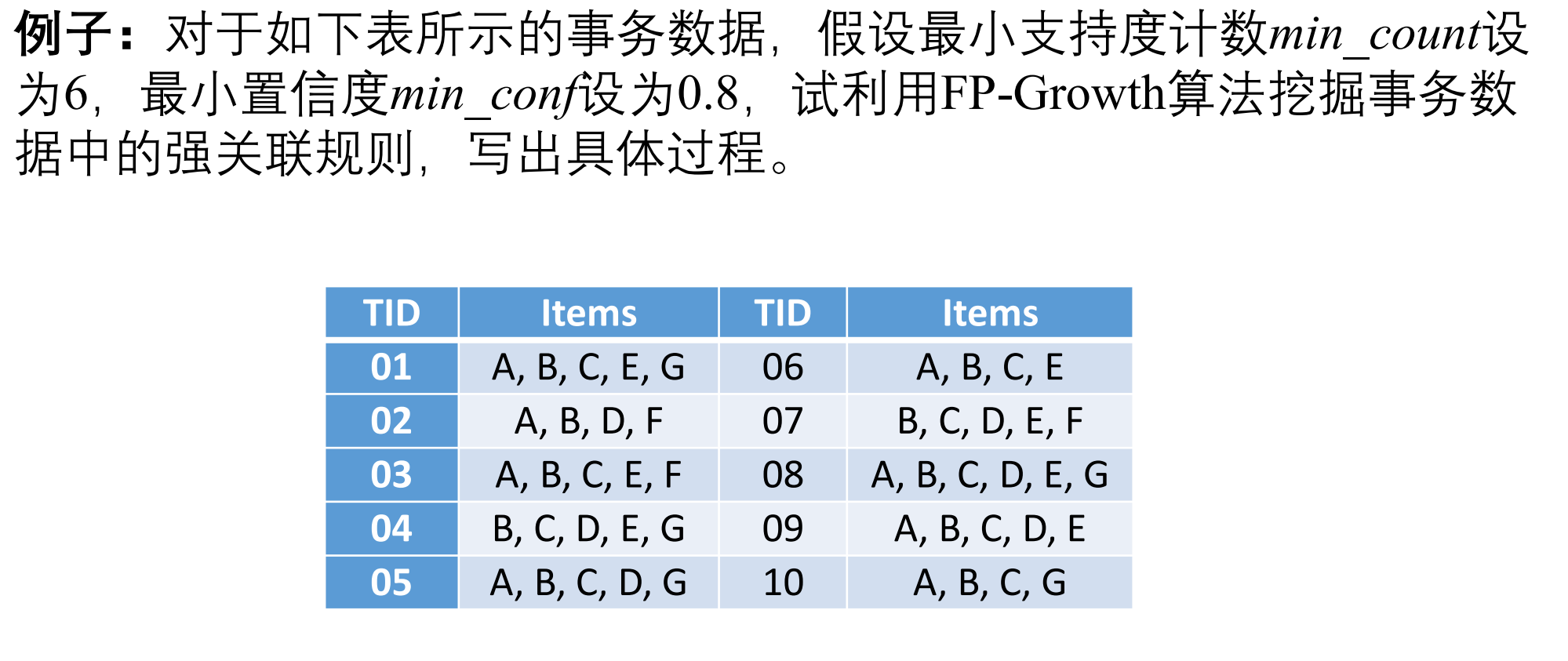
步骤一: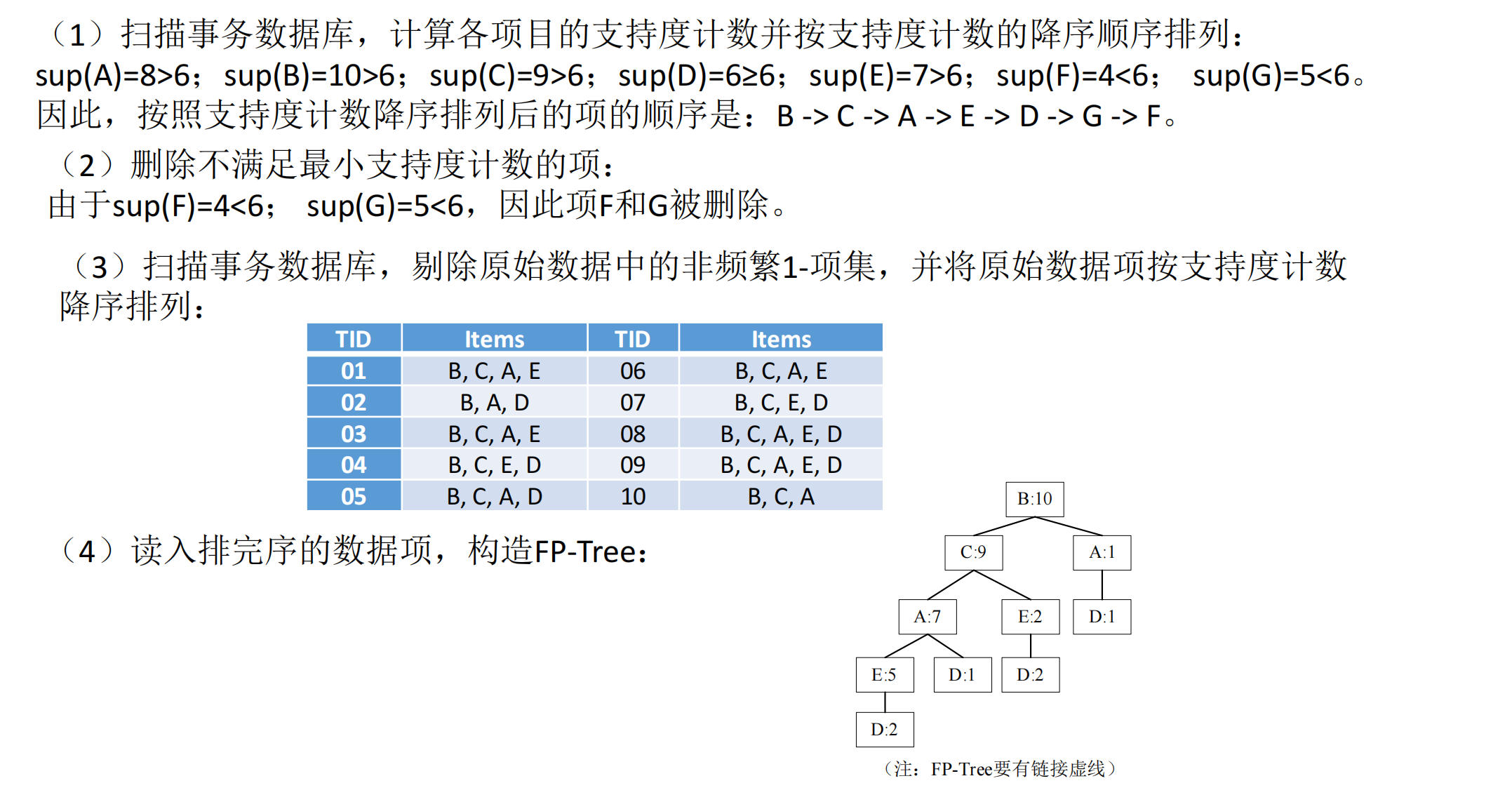
步骤二:
步骤三: